
Tesla has received U.S. Patent 12,618,976 B2, titled “Annotation Cross-Labeling for Autonomous Control Systems,” a filing that lays out a way to turn easy 2D image labels into precise 3D annotations for autonomous systems. Patent records list Anting Shen as inventor, Tesla, Inc. as assignee, and May 5, 2026 as the grant date, with the filing tied to an earlier patent family that includes U.S. Patents 11,361,457 B2 and 11,841,434 B2.
Why 3D labels are hard
Teaching a vehicle to spot an object in a camera frame is far simpler than labeling the same object inside a point cloud or depth map from an active sensor. The filing treats those second-sensor measurements as data from lidar, radar, or other depth sources, and those feeds are harder to label than a flat image. But a full 3D scene can be sparse and noisy, so software that scans the entire space can use heavy compute and still land on the wrong cluster of data.
Tesla’s patent treats that bottleneck as a labeling problem. And that is where the new method starts.
How the system works
So what changed. Tesla’s system starts with a reference annotation in a first sensor feed, such as a 2D box in a camera image, then maps that label into a spatial region in a second sensor feed that represents the same scene in 3D. Patent text says the software identifies a characteristic object in 2D space, then locates the matching object in 3D space through that mapped region.
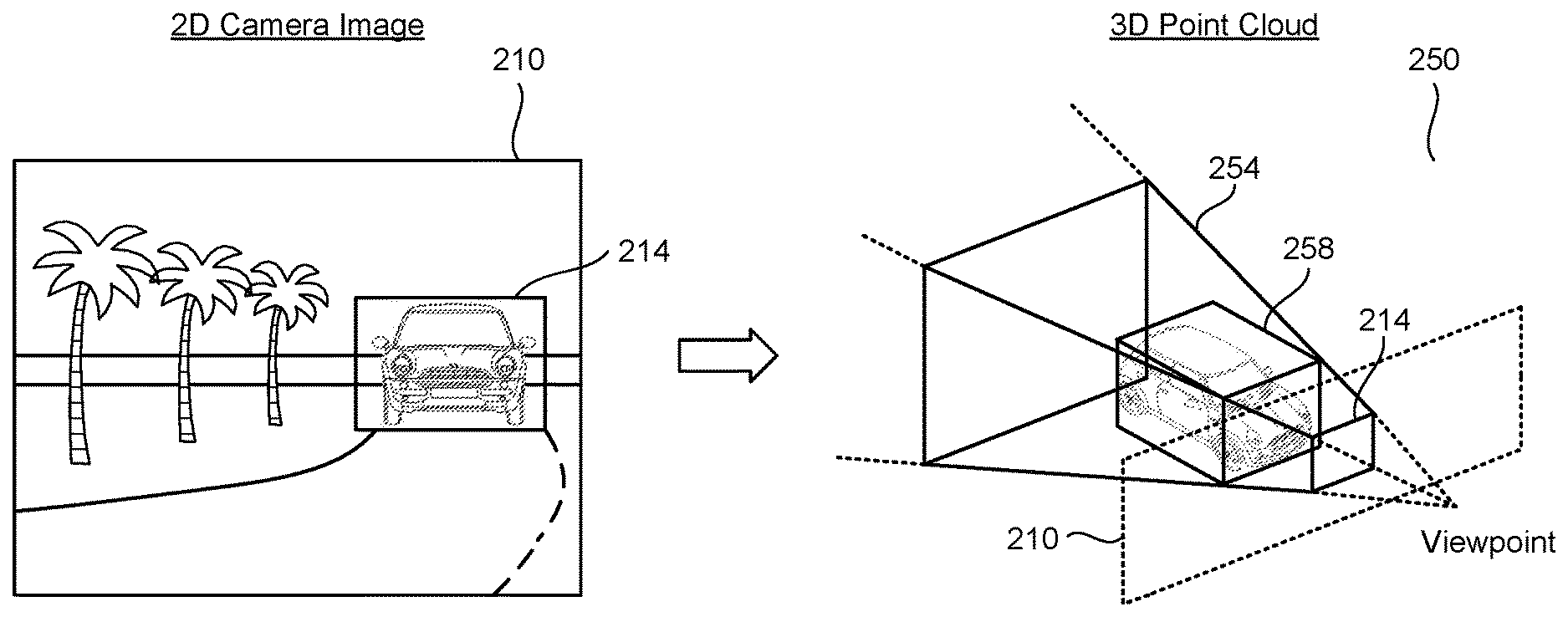
That region is described as a viewing frustum, a camera-based slice of space that narrows the search area for the 3D annotation model. Instead of searching a full point cloud, the model works inside that bounded zone and returns a 3D box or related annotation tied to the object.
Software and human review
The filing breaks the workflow into a data management module, a transformation module, and an annotation module. And each part has a clear job. The first stores synchronized sensor data, the second computes the geometry from 2D to 3D, and the third runs machine-learning models in that filtered region before sending the result to a human reviewer.
The patent adds that reviewers can verify or correct the output on client devices, which turns human labelers into editors of machine proposals instead of people drawing every 3D box by hand.
Yet the filing goes past bounding boxes. It says segmentation labels can move across sensor types too, so pixel-level labels in an image can help locate the matching 3D structure in a depth-based data set.
Meanwhile, the claims are broad enough to cover more than camera-to-lidar use, since the patent discusses first and second sensor sets in general and leaves room for pairings such as cameras with infrared, ultrasound, or other depth-sensing systems when the feeds are aligned.
Tesla says the annotated data can train several model types, including convolutional, deep, recurrent, and self-organizing map networks used in autonomous control systems.
Now that gives the patent value beyond a labeling tool, since it feeds the training pipeline for perception and higher-level driving tasks across Tesla’s autonomy work. And in practical terms, a system that cuts 3D search space with a camera-guided frustum can help Tesla process fleet data faster, with cleaner labels for Full Self-Driving development and possible use in future robotics work such as Optimus.
Patent

You may also like to read:
- Tesla files new patent to remove cabin heat and save battery life »
- Tesla files patent for new interior clip to stop cabin rattles »
- Tesla files patent for software-controlled 6-DOF hypercar seat frame »
- Tesla patent maps out occupant-based control for HOV and carpool access »
We’ve launched an official Tesla Owners Online Forum. Join early and claim your "Founding Fuel" badge.
